Interpretability Metrics
Contents
Interpreting the Models
While we may be able to achieve a relatively good accuracy score for our images, interpreting the results is crucial for both patients and physicians. Patients deserve to know why and how a diagnosis was obtained, and physicians should be in a position to discuss these results. Here, we investigate possible methods of interpreting the model.
Saliency Maps
At least to our own untrained eyes, it is somewhat difficult to distinguish the five classes in many of the training images, but we can identify areas of interest that might be important for a classification. This would likely be different for a trained radiologist – perhaps the saliency map can help us see what a radiologist might be trained to look for. The question is whether our model is using the same pixels as the ones we (or a radiologist) would to classify an image as a particular class.
model_0 = load_model('models/resnet50_model_0_best_weights.h5')
model_0.layers[-1].activation = activations.linear
model_0 = utils.apply_modifications(model_0)
model_2 = load_model('models/resnet50_model_2_best_weights.h5')
model_2.layers[-1].activation = activations.linear
model_2 = utils.apply_modifications(model_2)
model_5 = load_model('models/resnet50_model_5_best_weights.h5')
model_5.layers[-1].activation = activations.linear
model_5 = utils.apply_modifications(model_5)
In order to produce a saliency map most conducive to interpretation, we find the examples with the highest prediction probability for each model. We do so by having the model predict on 5000 images from the data generator, and then taking the highest probability images from each class, ensuring that the model predicts these examples correctly.
We have some suspicion our test data may be from a different distribution, so we experiment with interpreting images from the training set.
NOTE: The code below is an example what we used to produce the images. The actual images we chose are reported below this second to avoid running these cells unnecessarily.
#If it's class (key), should predict (value)
classes_to_pred_dict = {0:{0:0,1:1,2:2,3:3,4:4},
2:{0:None,1:0,2:1,3:3,4:3},
5:{0: None, 1: None, 2: 0, 3: None, 4: 1}}
def max_probabilities_each_class(probabilities, classes, data_df, c_to_p_dict):
class_indices_dict = {}
for i,p in enumerate(probabilities):
c = data_df.iloc[i]['class']
y_true = c_to_p_dict[c]
if y_true is not None:
if y_true not in class_indices_dict:
class_indices_dict[y_true] = (i,p[y_true])
else:
_, max_p = class_indices_dict[y_true]
if p[y_true] > max_p:
class_indices_dict[y_true] = (i,p[y_true])
return class_indices_dict
Resulting images for saliency mapping
saliency_imgs = {
0: {
0: {'p_max' : 1.0, 'filename' : 'c1.png'},
1: {'p_max' : 0.952381, 'filename' : 'c55588.png'},
2: {'p_max' : 0.999957, 'filename' : 'c51917.png'},
3: {'p_max' : 0.992362, 'filename' : 'c51993.png'},
4: {'p_max' : 0.999418, 'filename' : 'c45083.png'}},
2: {
0: {'p_max' : 0.999989, 'filename' : 'c26275.png'},
1: {'p_max' : 0.999996, 'filename' : 'c22152.png'},
2: {'p_max' : 1.0, 'filename' : 'c26083.png'},
3: {'p_max' : 1.0, 'filename' : 'c27278.png'}},
5: {
0: {'p_max' : 1.0, 'filename' : 'c1367.png'},
1: {'p_max' : 1.0, 'filename' : 'c26238.png'}}}
Saliency maps work by computing the gradient of the output category with respect to small changes in the input image. This method allows us to visualize which pixels contribute most to the classification, in that changing an “important” pixel or group of pixels would change the classification.
Below, we investigate three different methods of producing a saliency map. Normal/vanilla, guided, and relu/rectified. Guided saliency restricts backpropagation to only positive gradients for positive activations, while relu saliency restricts to only positive gradient information.
def display_saliency_maps(model, classes_dict):
for class_idx in classes_dict.keys():
f, ax = plt.subplots(1, 4)
im = plt.imread('data/train_images/' + classes_dict[class_idx]['filename'])
im = np.stack((im.reshape((299,299)),)*3, axis=-1)
ax[0].imshow(im)
layer_idx = -1
for i, modifier in enumerate([None, 'guided', 'relu']):
grads = visualize_saliency(model, layer_idx, filter_indices=class_idx,
seed_input=im, backprop_modifier=modifier)
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
ax[i+1].imshow(grads, cmap='jet')
[a.axis('off') for a in ax]
Model 0: Raw Pre-Processed DDSM Dataset (Classes 0 to 4)
display_saliency_maps(model_0, saliency_imgs[0])
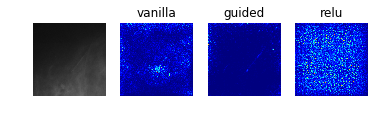



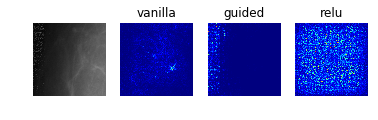
Especially noteworthy is the fact that model 0 identifies a particular point near the center of the first image (corresponding to a case with no mass or calcification) as being a salient indicator of the normality of this case. It may be that this concentrated region of high-saliency in the “vanilla” saliency map indicates that it is because the model did not see a feature at this location (which is perhaps the average location for where the masses/calcifications are located in the training set images) that suggests the image corresponds to a normal case. This would seem to undermine our initial suspicion that the model was so successful at identifying normal cases because it was relying on some property of the image itself (e.g. the distribution of pixel intensities) rather than the absence of a suspicious abnormality.
Model 2: Classification of Abnormalities (Classes 1 to 4)
display_saliency_maps(model_2, saliency_imgs[2])
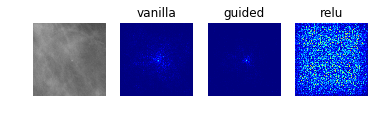

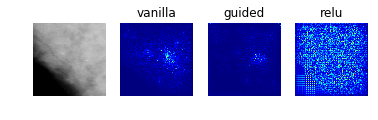

The model appears to have correctly identified the location of the abnormalities, though it is difficult for us to determine from these particular saliency maps (though perhaps would not be to a trained radiologist) what in particular about each abnormality caused the model to classify it among the four possible classes. We attempted to better understand what subportions of the abnormalities caused the classifier to differentiate among the “positive” classes by using Local Interpretable Model-Agnostic Explanations (LIME), as discussed below.
Model 5: Benign vs Malignant Mass
display_saliency_maps(model_5, saliency_imgs[5])


As with the results from model 2, these saliency maps make clear that model 5 has correctly identified the mass as the crucial feature in the image, though again it is not obvious what specific aspects of the mass led the classifier identify it as benign or malignant.
Local Interpretable Model-Agnostic Explanations (LIME)
As a local surrogate model, LIME performs image segmentation to identify super-pixels in an single input image, then measures how the output of the model changes as super-pixels are included or omitted (“perturbing” the input). In this way, LIME clearly identifies which contiguous regions of the input contribute to the model’s decision, and would therefore appear to be a valuable addition to the saliency maps, which did not offer clear a perspective into what features of the images the model used to identify among types of abnormalities.

However, we were unable to extract meaningful results from LIME, as shown below. This was in part due to the fact that many of the classification decisions appeared to be made because of the absence of not-obviously-meaningful content in the images. Additionally, it is well-documented that LIME is highly sensitive to the choice of segmentation-algorithm parameters, which influence which super-pixels are identified.$^1$
[1] Molnar, Christoph. “Interpretable machine learning. A Guide for Making Black Box Models Explainable”, 2019. https://christophm.github.io/interpretable-ml-book/.
Model 2
model_2 = load_model('models_updated/resnet50_model_2_best_weights.h5')
m2_c1_img = cv2.imread('images/' + "c26275.png")
m2_c2_img = cv2.imread('images/' + "c22152.png")
m2_c3_img = cv2.imread('images/' + "c26083.png")
m2_c4_img = cv2.imread('images/' + "c27278.png")
Class 1: Benign Calcification
explanation1 = explainer.explain_instance(m2_c1_img, model_2.predict, top_labels=4, hide_color=0, num_samples=1000)
temp, mask = explanation1.get_image_and_mask(0, positive_only=False, num_features=5, hide_rest=True)
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(m2_c1_img)
axes[1].imshow(mark_boundaries(temp / 2 + 0.5, mask))
[ax.axis('off') for ax in axes];
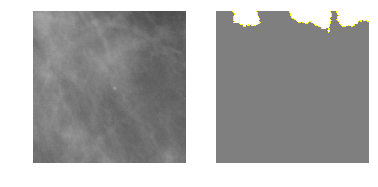
Class 2: Benign Mass
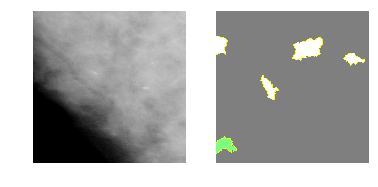
explanation2 = explainer.explain_instance(m2_c2_img, model_2.predict, top_labels=4, hide_color=0, num_samples=1000)
temp, mask = explanation2.get_image_and_mask(1, positive_only=False, num_features=5, hide_rest=True)
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(m2_c2_img)
axes[1].imshow(mark_boundaries(temp / 2 + 0.5, mask))
[ax.axis('off') for ax in axes];

Class 3: Malignant Calcification
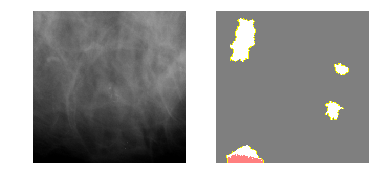
explanation3 = explainer.explain_instance(m2_c3_img, model_2.predict, top_labels=4, hide_color=0, num_samples=1000)
temp, mask = explanation3.get_image_and_mask(2, positive_only=False, num_features=5, hide_rest=True)
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(m2_c3_img)
axes[1].imshow(mark_boundaries(temp / 2 + 0.5, mask))
[ax.axis('off') for ax in axes];
Class 4: Malignant Mass
explanation4 = explainer.explain_instance(m2_c4_img, model_2.predict, top_labels=4, hide_color=0, num_samples=1000)
temp, mask = explanation4.get_image_and_mask(3, positive_only=False, num_features=5, hide_rest=True)
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(m2_c4_img)
axes[1].imshow(mark_boundaries(temp / 2 + 0.5, mask))
[ax.axis('off') for ax in axes];
Model 5
model_5 = load_model('models_updated/resnet50_model_5_best_weights.h5')
m5_c0_img = cv2.imread('images/' + "c1367.png")
m5_c1_img = cv2.imread('images/' + "c26238.png")
Class 0: Benign Mass
explanation0 = explainer.explain_instance(m5_c0_img, model_5.predict, top_labels=2, hide_color=0, num_samples=1000)
temp, mask = explanation0.get_image_and_mask(0, positive_only=False, num_features=5, hide_rest=True)
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(m5_c0_img)
axes[1].imshow(mark_boundaries(temp / 2 + 0.5, mask))
[ax.axis('off') for ax in axes];

Class 1: Malignant Mass
explanation1 = explainer.explain_instance(m5_c1_img, model_5.predict, top_labels=2, hide_color=0, num_samples=1000)
temp, mask = explanation1.get_image_and_mask(1, positive_only=False, num_features=5, hide_rest=True)
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(m5_c1_img)
axes[1].imshow(mark_boundaries(temp / 2 + 0.5, mask))
[ax.axis('off') for ax in axes];

SHapley Additive exPlanations (SHAP)
We were unfortunately unable to exploit Shapley values as yet another alternative to the two previous interpretability metrics given resource constraints. With more time, we would have been interested in investigating Deep SHAP, which approximates SHAP values in order to reduce the algorithm’s complexity, enabling it to be used for deep learning models.

train_df_model_2 = pd.read_csv('data/train_df_model_2.csv')
# select a set of background examples to take an expectation over
background_paths = np.random.choice(train_df_model_2['filename'], 50, replace=False)
background = [plt.imread('images/' + path)*(1./255) for path in background_paths]
background = [np.stack((im.reshape((299,299)),)*3, axis=-1) for im in background]
background = np.array(background)
# explain predictions of the model on four images
e = shap.DeepExplainer(model_2, background)
shap_values = e.shap_values(background[1:5])
# plot the feature attributions
shap.image_plot(shap_values, -background[1:5])
ResourceExhaustedErrorTraceback (most recent call last)
<ipython-input-26-0c6e18dc3915> in <module>()
----> 1 shap_values = e.shap_values(background[1:5])
2
3 # plot the feature attributions
4 shap.image_plot(shap_values, -background[1:5])
/usr/local/lib/python2.7/dist-packages/shap/explainers/deep/__init__.pyc in shap_values(self, X, ranked_outputs, output_rank_order)
117 were chosen as "top".
118 """
--> 119 return self.explainer.shap_values(X, ranked_outputs, output_rank_order)
/usr/local/lib/python2.7/dist-packages/shap/explainers/deep/deep_tf.pyc in shap_values(self, X, ranked_outputs, output_rank_order)
260 # run attribution computation graph
261 feature_ind = model_output_ranks[j,i]
--> 262 sample_phis = self.run(self.phi_symbolic(feature_ind), self.model_inputs, joint_input)
263
264 # assign the attributions to the right part of the output arrays
/usr/local/lib/python2.7/dist-packages/shap/explainers/deep/deep_tf.pyc in run(self, out, model_inputs, X)
280 for t in self.learning_phase_flags:
281 feed_dict[t] = False
--> 282 return self.session.run(out, feed_dict)
283
284 def custom_grad(self, op, *grads):
/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.pyc in run(self, fetches, feed_dict, options, run_metadata)
927 try:
928 result = self._run(None, fetches, feed_dict, options_ptr,
--> 929 run_metadata_ptr)
930 if run_metadata:
931 proto_data = tf_session.TF_GetBuffer(run_metadata_ptr)
/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.pyc in _run(self, handle, fetches, feed_dict, options, run_metadata)
1150 if final_fetches or final_targets or (handle and feed_dict_tensor):
1151 results = self._do_run(handle, final_targets, final_fetches,
-> 1152 feed_dict_tensor, options, run_metadata)
1153 else:
1154 results = []
/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.pyc in _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata)
1326 if handle is None:
1327 return self._do_call(_run_fn, feeds, fetches, targets, options,
-> 1328 run_metadata)
1329 else:
1330 return self._do_call(_prun_fn, handle, feeds, fetches)
/usr/local/lib/python2.7/dist-packages/tensorflow/python/client/session.pyc in _do_call(self, fn, *args)
1346 pass
1347 message = error_interpolation.interpolate(message, self._graph)
-> 1348 raise type(e)(node_def, op, message)
1349
1350 def _extend_graph(self):
ResourceExhaustedError: OOM when allocating tensor with shape[200,75,75,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[node gradients_1/resnet50/conv1_pad/Pad_grad/Slice_1 (defined at /usr/local/lib/python2.7/dist-packages/shap/explainers/deep/deep_tf.py:494) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.