CNN with Data Augmentation
Contents
Convolutional Neural Network
Summary
In this notebook we try to improve upon the CNN we built from scratch by adding data augmentation (without changing the structure at all).
Data Augmentation
We added horizontal flips, a random colour channel shift of 20%, as well as dropout (randomly dropping 10% of input at each update) for our data augmentation.
Results
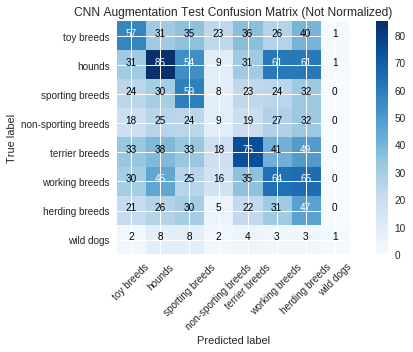
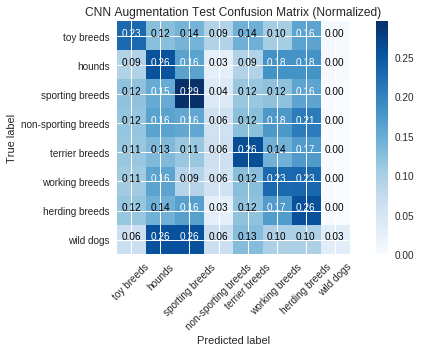
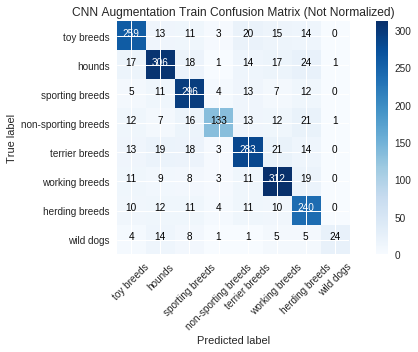
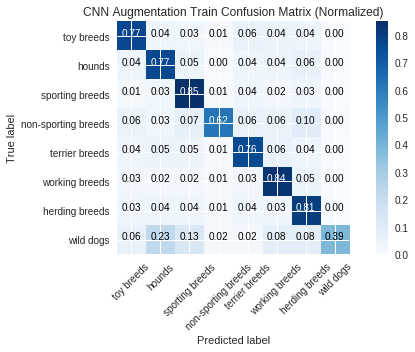
The CNN model with augmentation took about 18.5 minutes to train and had a training accuracy of 77.2% and a test accuracy of 22.9%. Without augmentation, the training accuracy was 99.3% and the test accuracy was 22.5%.
The test categorical loss with augmentation was 2.503, compared to 5.886 without augmentation.
Compared to the original CNN we built from scratch, data augmentation appears to cause the model to be less overfit to the training set and yields slightly better performance on the test set.
In particular the categorical loss is improved a lot with data augmentation, even though the accuracy score is only marginally improved.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
import matplotlib.image as mpimg
import os
%matplotlib inline
import keras
from keras.layers import Conv2D, MaxPooling2D, Dense, Input, Flatten, Dropout, UpSampling2D, GlobalAveragePooling2D
from keras.models import Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
from keras.utils import np_utils
from keras.datasets import cifar10
import pandas as pd
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
from IPython.display import Image, display
import random, os
Using TensorFlow backend.
#Make sure you're using GPU
!nvidia-smi
Wed Dec 12 19:49:57 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.44 Driver Version: 396.44 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 71C P8 34W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
##Build Directories
!rm -rf 'train'
!rm -rf 'test'
!rm -rf 'train_partial'
!rm -rf 'test_partial'
!unzip 'train.zip'
!unzip 'train_partial.zip'
!unzip 'test.zip'
!unzip 'test_partial.zip'
!rm 'test/test.zip'
!rm 'train/train.zip'
rm: cannot remove 'test/test.zip': No such file or directory
rm: cannot remove 'train/train.zip': No such file or directory
!ls test
0 1 2 3 4 5 6 7
test_imgs_count = sum([len(files) for r, d, files in os.walk("test")])
test_partial_imgs_count = sum([len(files) for r, d, files in os.walk("test_partial")])
print("Test images: {}, partial test images: {}".format(test_imgs_count, test_partial_imgs_count))
Test images: 8580, partial test images: 1716
train_imgs_count = sum([len(files) for r, d, files in os.walk("train")])
train_partial_imgs_count = sum([len(files) for r, d, files in os.walk("train_partial")])
print("Train images: {}, partial train images: {}".format(train_imgs_count, train_partial_imgs_count))
Train images: 11999, partial train images: 2400
There are 11999 total training images, so we can choose a batch size of 13 or 71 as numbers closest to 32. There are 2400 partial train images so we can choose a batch size of 32.
batch_size_train = 71
batch_size_test = 1
batch_size_train_partial = 32
batch_size_test_partial = 1
##Build Models
train_datagen = ImageDataGenerator(
rescale=1./255,
horizontal_flip = True,
channel_shift_range = 0.20)
#consider adding horizontal flip = true here
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
directory=r"./train/",
target_size=(224, 224),
color_mode="rgb",
batch_size=batch_size_train,
class_mode="categorical",
shuffle=True,
seed=42
)
test_generator = test_datagen.flow_from_directory(
directory=r"./test/",
target_size=(224, 224),
color_mode="rgb",
batch_size=1,
class_mode="categorical",
shuffle=False,
seed=42
)
optimizer = Adam(lr=0.0001)
Found 11999 images belonging to 8 classes.
Found 8580 images belonging to 8 classes.
train_partial_datagen = ImageDataGenerator(
rescale=1./255)
#consider adding horizontal flip = true here
test_partial_datagen = ImageDataGenerator(rescale=1./255)
train_partial_generator = train_datagen.flow_from_directory(
directory=r"./train_partial/",
target_size=(224, 224),
color_mode="rgb",
batch_size=batch_size_train_partial,
class_mode="categorical",
shuffle=False,
seed=42
)
test_partial_generator = test_datagen.flow_from_directory(
directory=r"./test_partial/",
target_size=(224, 224),
color_mode="rgb",
batch_size=1,
class_mode="categorical",
shuffle=False,
seed=42
)
optimizer = Adam(lr=0.0001)
Found 2400 images belonging to 8 classes.
Found 1716 images belonging to 8 classes.
Original CNN
inp = Input(shape = (224,224,3))
x = Dropout(0.15)(inp)
x = Conv2D(32, (5,5), strides=(1, 1), padding='same', activation='relu', use_bias=True)(x)
x = Conv2D(32, (3,3), strides=(1, 1), padding='same', activation='relu', use_bias=True)(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2,2), padding='same', data_format=None)(x)
x = Conv2D(64, (3,3), strides=(1, 1), padding='same', activation='relu', use_bias=True)(x)
x = Conv2D(64, (3,3), strides=(1, 1), padding='same', activation='relu', use_bias=True)(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2,2), padding='same', data_format=None)(x)
x = Conv2D(128, (3,3), strides=(1, 1), padding='same', activation='relu', use_bias=True)(x)
x = Conv2D(128, (3,3), strides=(1, 1), padding='same', activation='relu', use_bias=True)(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2,2), padding='same', data_format=None)(x)
x = Flatten()(x)
x = Dense(512, activation='relu')(x)
x = Dense(8, activation='softmax')(x)
model_aug = Model(inputs=inp, outputs= x)
model_aug.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
STEP_SIZE_TRAIN=train_generator.n//train_generator.batch_size
model_aug.fit_generator(generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=10
)
Epoch 1/10
169/169 [==============================] - 113s 671ms/step - loss: 1.9970 - acc: 0.1739
Epoch 2/10
169/169 [==============================] - 110s 650ms/step - loss: 1.9582 - acc: 0.2119
Epoch 3/10
169/169 [==============================] - 110s 651ms/step - loss: 1.9236 - acc: 0.2376
Epoch 4/10
169/169 [==============================] - 110s 652ms/step - loss: 1.8873 - acc: 0.2590
Epoch 5/10
169/169 [==============================] - 110s 650ms/step - loss: 1.8368 - acc: 0.2896
Epoch 6/10
169/169 [==============================] - 110s 652ms/step - loss: 1.7749 - acc: 0.3215
Epoch 7/10
169/169 [==============================] - 110s 652ms/step - loss: 1.6736 - acc: 0.3744
Epoch 8/10
169/169 [==============================] - 110s 652ms/step - loss: 1.5106 - acc: 0.4480
Epoch 9/10
169/169 [==============================] - 110s 653ms/step - loss: 1.2839 - acc: 0.5522
Epoch 10/10
169/169 [==============================] - 110s 653ms/step - loss: 0.9737 - acc: 0.6758
<keras.callbacks.History at 0x7fc3e053ceb8>
##Loss and Accuracy Scores
###ResNet50
#train accuracy
train_generator.reset()
model_aug.evaluate_generator(train_generator, steps=(train_imgs_count/batch_size_train))
[0.7555321239860806, 0.7725643794212116]
#test accuracy
test_generator.reset()
model_aug.evaluate_generator(test_generator, steps=(test_imgs_count/batch_size_test))
[2.5033201030445627, 0.2287878787878788]
model_aug.metrics_names
['loss', 'acc']
##Confusion Matrices
%run -i 'metrics_script.py'
<matplotlib.figure.Figure at 0x7fc3d7174ac8>
###ResNet50
train_partial_generator.reset()
y_pmf_train = model_aug.predict_generator(train_partial_generator,steps=train_partial_generator.n/batch_size_train_partial,verbose=1)
75/75 [==============================] - 10s 134ms/step
y_pred_train = np.argmax(y_pmf_train,axis=1).astype(np.str)
y_true_train = [n[0] for n in train_partial_generator.filenames]
model_name_train = "CNN Augmentation Train"
test_partial_generator.reset()
y_pmf_test = model_aug.predict_generator(test_partial_generator,steps=test_partial_generator.n/batch_size_test_partial,verbose=1)
1716/1716 [==============================] - 17s 10ms/step
y_pred_test = np.argmax(y_pmf_test,axis=1).astype(np.str)
y_true_test = [n[0] for n in test_partial_generator.filenames]
model_name_test = "CNN Augmentation Test"
labels = ["toy breeds", "hounds", "sporting breeds", "non-sporting breeds", "terrier breeds", "working breeds", "herding breeds", "wild dogs"]
run_metrics(y_pred_train, y_pmf_train, y_true_train, model_name_train, labels=labels)
Categorical Loss: 0.0
Accuracy Score: 0.7720833333333333
(0.0, 0.7720833333333333)
run_metrics(y_pred_test, y_pmf_test, y_true_test, model_name_test, labels=labels)
Categorical Loss: 0.0
Accuracy Score: 0.23135198135198135
(0.0, 0.23135198135198135)