Baseline Models
Contents
- Summary
- Data Preparation
- Model Creation and Prediction
- Plurality Model Results
- Uniformly Random Model Results
Summary
We picked two (very) baseline models.
- Random class prediction.
- Plurality class prediction.
It is unsurprising that the baseline models metrics (accuracy score, etc) are comparable because there are roughly equal samples for each breed in the training set. We see that the majority prediction still performs slightly better than the randomized prediction, but both are close to $1/8 = 12.5\%$ accuracy, again unsurprisingly considering that there are 8 classes. We expect the other models to perform substantially better.
Data Preparation
%matplotlib inline
import matplotlib.pyplot as plt
import random
import pandas as pd
import numpy as np
import itertools
import time
from sklearn.metrics import log_loss
from sklearn.metrics import accuracy_score
from keras.utils import to_categorical
from sklearn.metrics import confusion_matrix
Using TensorFlow backend.
train_df = pd.read_csv('raw_train_df.csv', index_col=0)
test_df = pd.read_csv('raw_test_df.csv', index_col=0)
x_train, y_train = train_df['original_path'], train_df['class']
x_test, y_test = test_df['original_path'], test_df['class']
majority_class = y_train.mode()[0]
NUM_CLASSES = 8
super_classes = ['toy breeds', 'hounds', 'sporting breeds', 'non-sporting breeds', 'terrier breeds',
'working breeds', 'herding breeds', 'wild dogs']
Model Creation and Prediction
The two baseline models are created below. The plurality model predicts the most common class, and the random model predicts a random class. These models predict with “100% certainty” in the sense that they predict a single class instead of generating probabilities of which class a certain element belongs to.
Model Creation
def predict_plurality(x):
predictions = np.ones(len(x)) * majority_class
pmf = to_categorical(predictions, num_classes=NUM_CLASSES)
answer = (np.zeros(8)) * len(x)
return predictions, pmf
def random_prediction(x):
pred = np.random.choice(range(8), len(x))
return pred, to_categorical(pred, 8)
Model Predictions
Note that model predictions are timed.
start = time.time()
y_train_pred_plurality, y_train_pmf_plurality = predict_plurality(x_train)
plurality_train_time = time.time() - start
start = time.time()
y_train_pred_random, y_train_pmf_random = random_prediction(x_train)
plurality_test_time = time.time() - start
start = time.time()
y_test_pred_plurality, y_test_pmf_plurality = predict_plurality(x_test)
random_train_time = time.time() - start
start = time.time()
y_test_pred_random, y_test_pmf_random = random_prediction(x_test)
random_test_time = time.time() - start
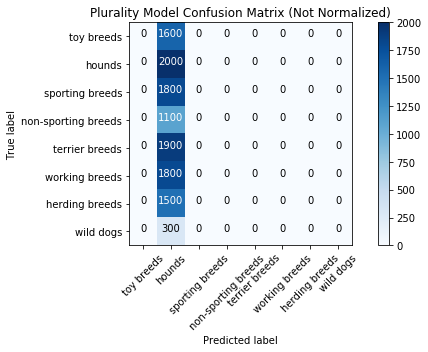
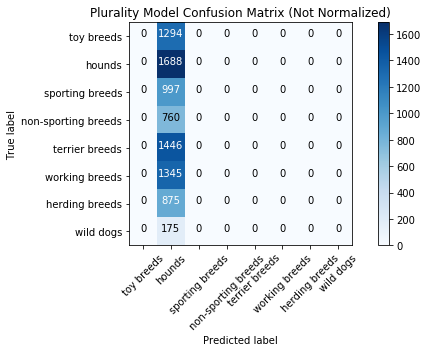
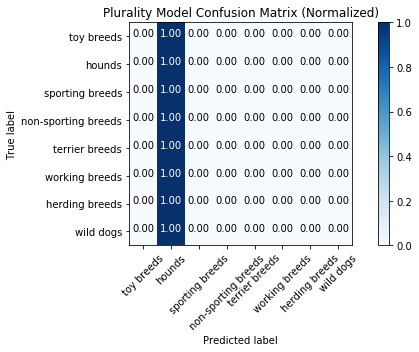
Plurality Model Results
The function to generate the results and confusion table, as well as plot the confusion table, is in “metrics_script.py”.
%run -i 'metrics_script.py'
Training Set
plurality_train_loss, plurality_train_acc = run_metrics(y_train_pred_plurality,
y_train_pmf_plurality,
y_train,
"Plurality Model",
plurality_train_time)
Categorical Loss: 28.78231366475423
Accuracy Score: 0.16666666666666666
Runtime: 0.0014190673828125
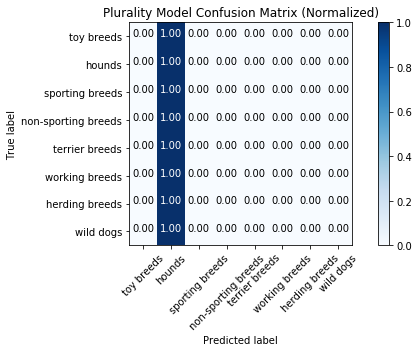
Test Set
plurality_test_loss, plurality_test_acc = run_metrics(y_test_pred_plurality,
y_test_pmf_plurality,
y_test,
"Plurality Model",
plurality_test_time)
Categorical Loss: 27.74373507377429
Accuracy Score: 0.19673659673659674
Runtime: 0.0007889270782470703
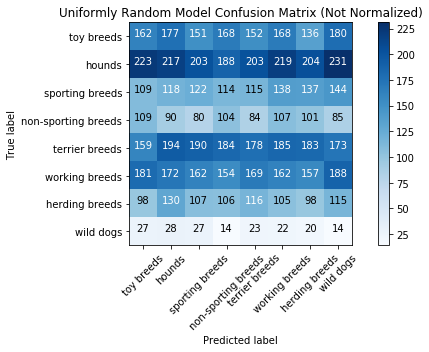
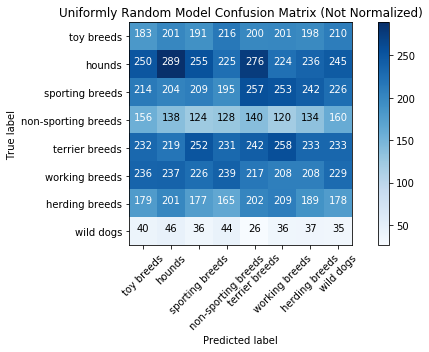
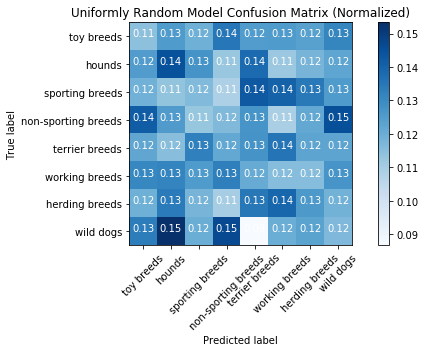
Uniformly Random Model Results
Training Set
random_train_loss, random_train_acc = run_metrics(y_train_pred_random,
y_train_pmf_random,
y_train,
"Uniformly Random Model",
random_train_time)
Categorical Loss: 30.270359281222024
Accuracy Score: 0.12358333333333334
Runtime: 0.0008828639984130859
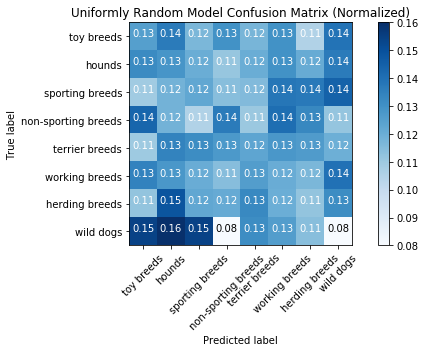
Test Set
random_test_loss, random_test_acc = run_metrics(y_test_pred_random,
y_test_pmf_random,
y_test,
"Uniformly Random Model",
random_test_time)
Categorical Loss: 30.283824573419032
Accuracy Score: 0.1231934731934732
Runtime: 0.0006747245788574219